
依托大模型与云计算协同发展,拥抱 AI 时代
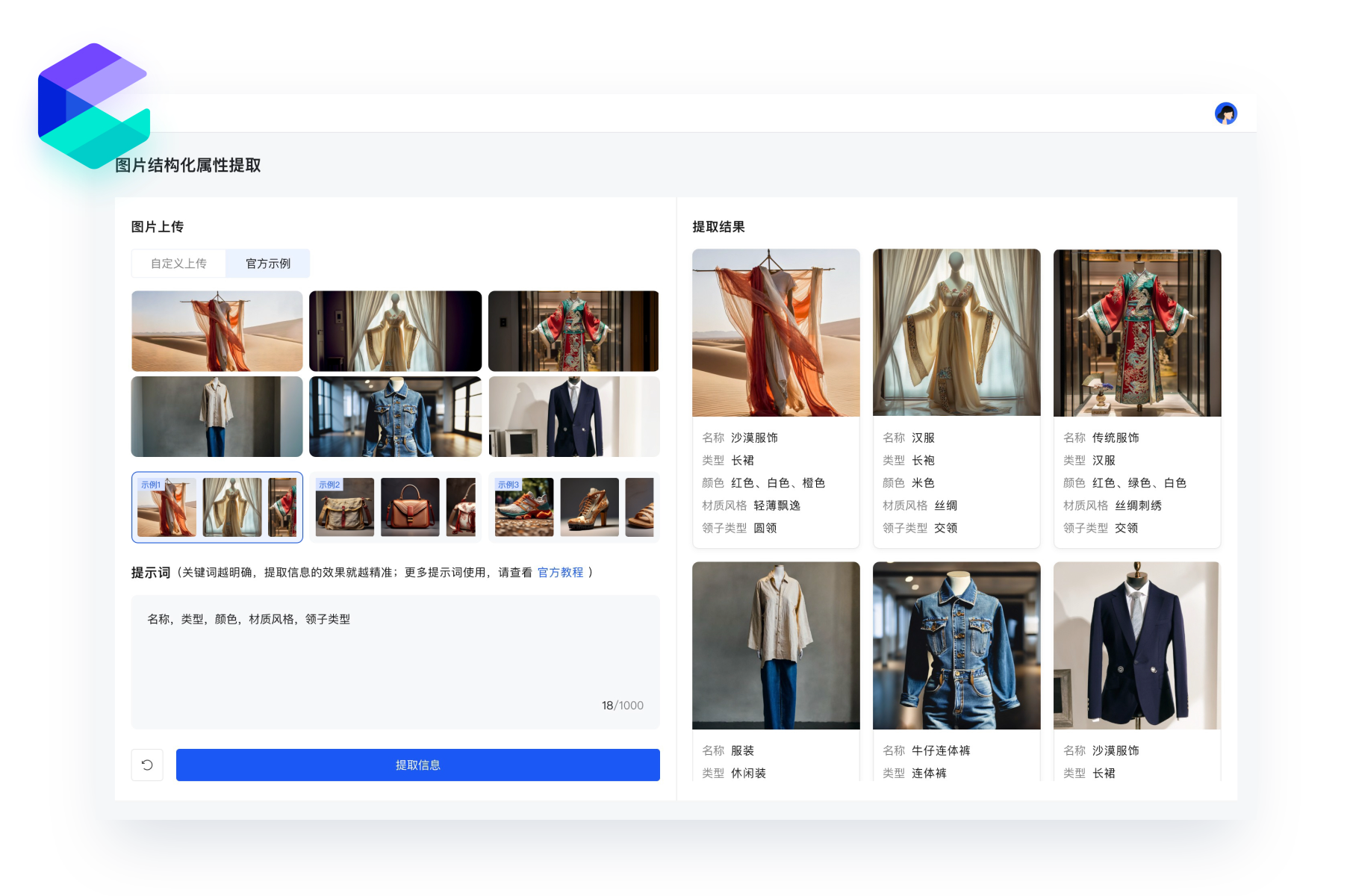
多模态信息提取
开箱即用,通过百炼的多模态大模型推理服务,能够识别和解析文本、图像、音视频等不同模态的数据,根据用户需求进行结构化信息挖掘、提取、分析和摘要等,并支持批处理模式下的离线作业,提高大规模数据处理效率,降低 50% 的业务落地成本。
相关云产品
技术实现参考
① 通过使用函数计算构建的 Web 应用来接收用户的请求。
② 在接收到请求后,将图片文件自动上传至对象存储服务 OSS,以便后续处理。
③ 当需要执行信息提取时,Web 应用会将文本、文档、图片、视频相关信息及相关提示词一并发送给百炼平台。
④ 百炼平台根据所提交的数据,调用文本或视觉模型进行分析处理,并生成结果。
⑤ 处理完成后,百炼平台将结果返回给 Web 应用,再由 Web 应用将最终的信息提取结果呈现给用户。
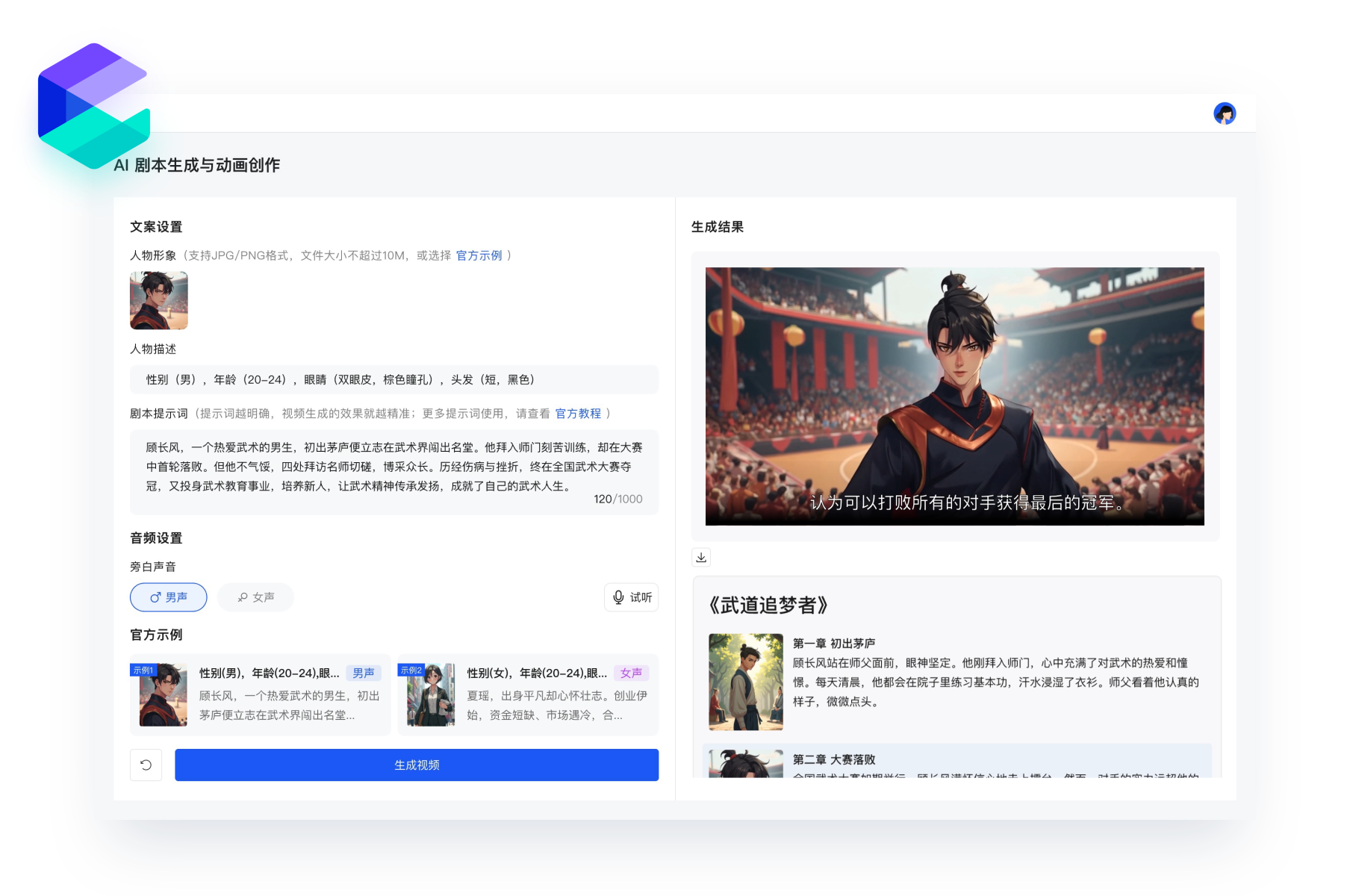
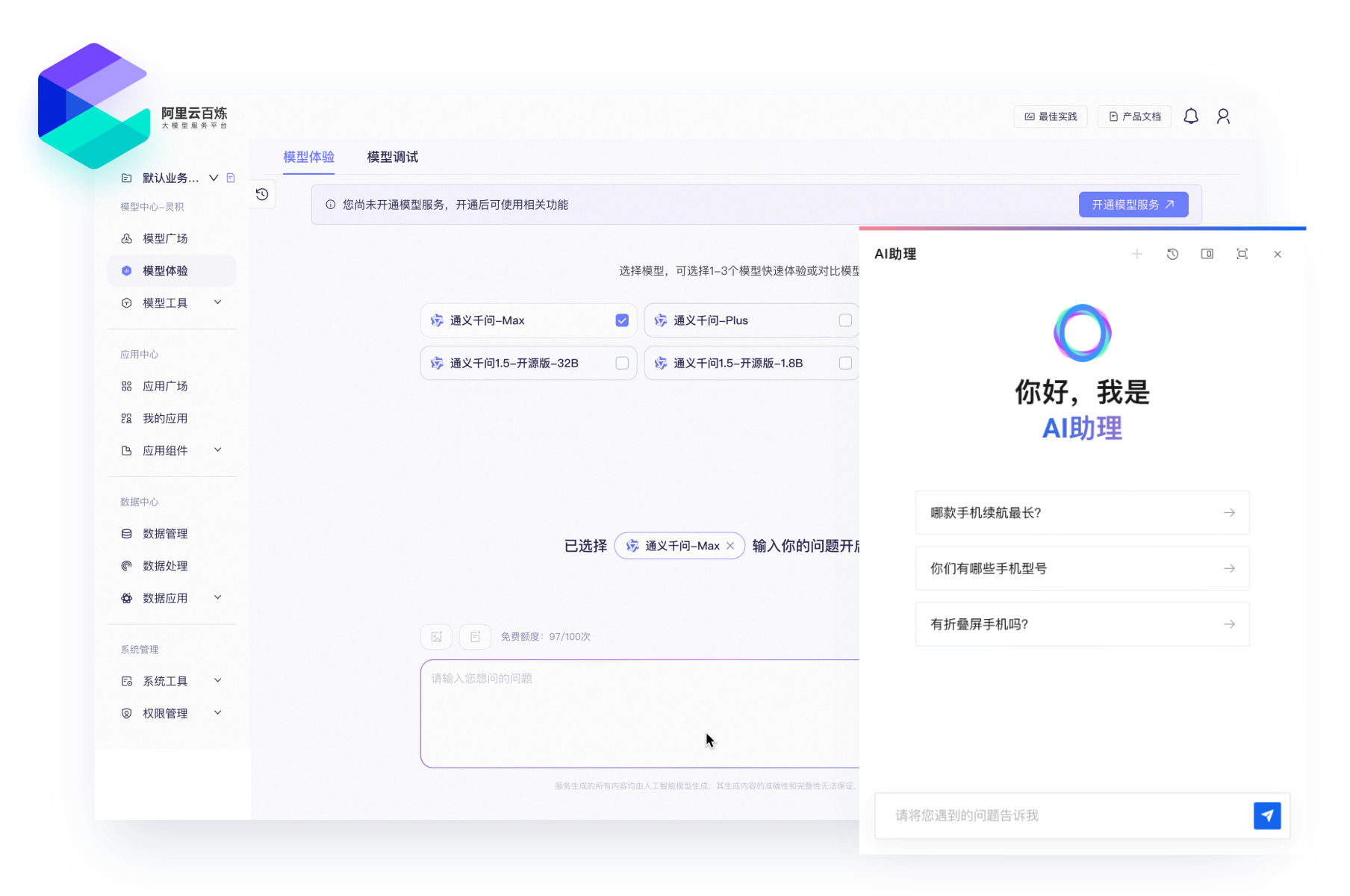
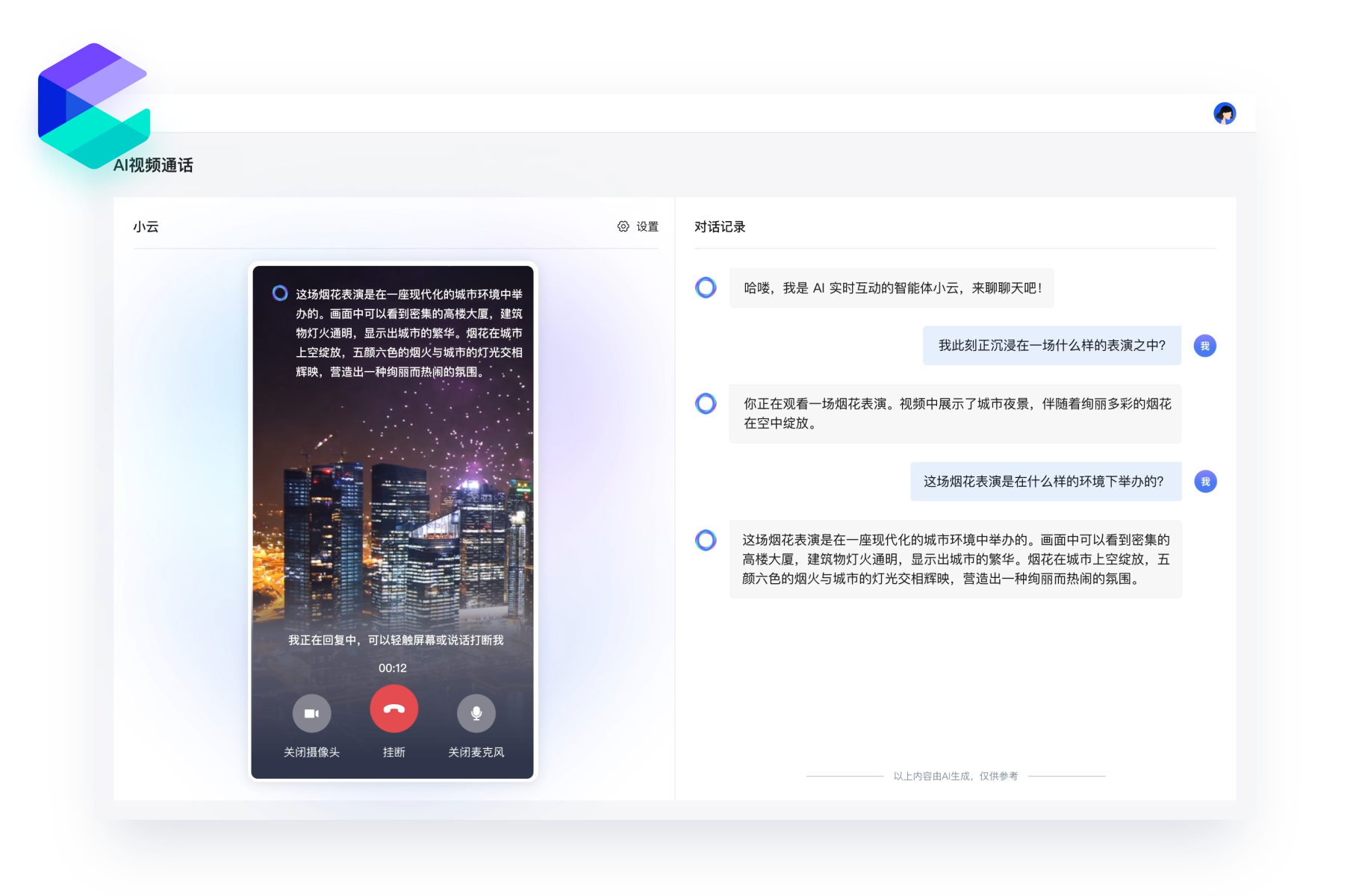
10 分钟构建 AI 客服
只需 10 分钟即可构建一个 AI 客服,并发布到网站、钉钉、微信公众号或企业微信中,以便全天候(7×24)回应客户咨询,同时可以为大模型应用配置知识库,增强检索,让其更加精准且专业地回答与商品相关的问题,提升用户体验。
相关云产品
技术实现参考
① 创建大模型应用:通过百炼创建一个大模型应用,并获取调用大模型应用 API 的相关凭证。
② 引入 AI 客服:通过修改前端 HTML 代码,实现在网站中引入一个 AI 客服。
③ 增加私有知识:准备一些私有知识,让 AI 客服能回答原本无法准确回答的问题,更好的应对客户咨询。
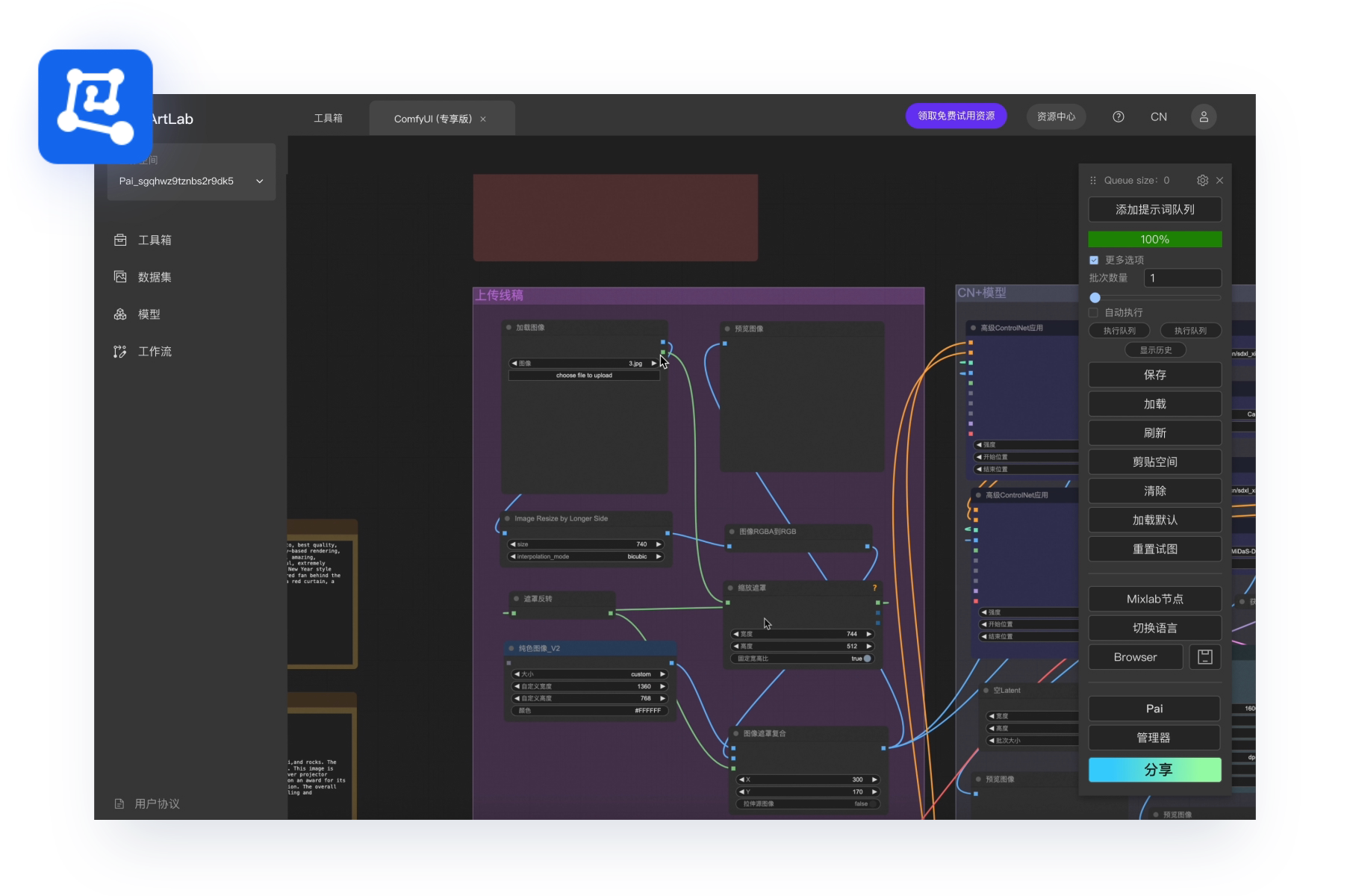
AI 打造专属企业风格海报
即开即用,加速设计生产力,使用 PAI-ArtLab 快速生成符合企业特定风格的 Logo 商标图、设计图、宣传图、海报图等,用户无需编写程序即可利用 AI 能力完成设计工作,降低了使用门槛,大大节省了人力、时间成本,提高图片产出效率且保证图片生成质量。
相关云产品
技术实现参考
① 启动 ComfyUI 工作流:通过 PAI-ArtLab 开启 ComfyUI 专享版服务,并加载开箱即用的企业海报形象流程。
② 生成 AI 设计 Logo:上传已有的原始 Logo 图片,使用 AI 设计能力,生成新版 Logo 海报。
③ 调整出图效果:通过修改正向、反向提示词(prompt),调整海报风格,获得最终成品。
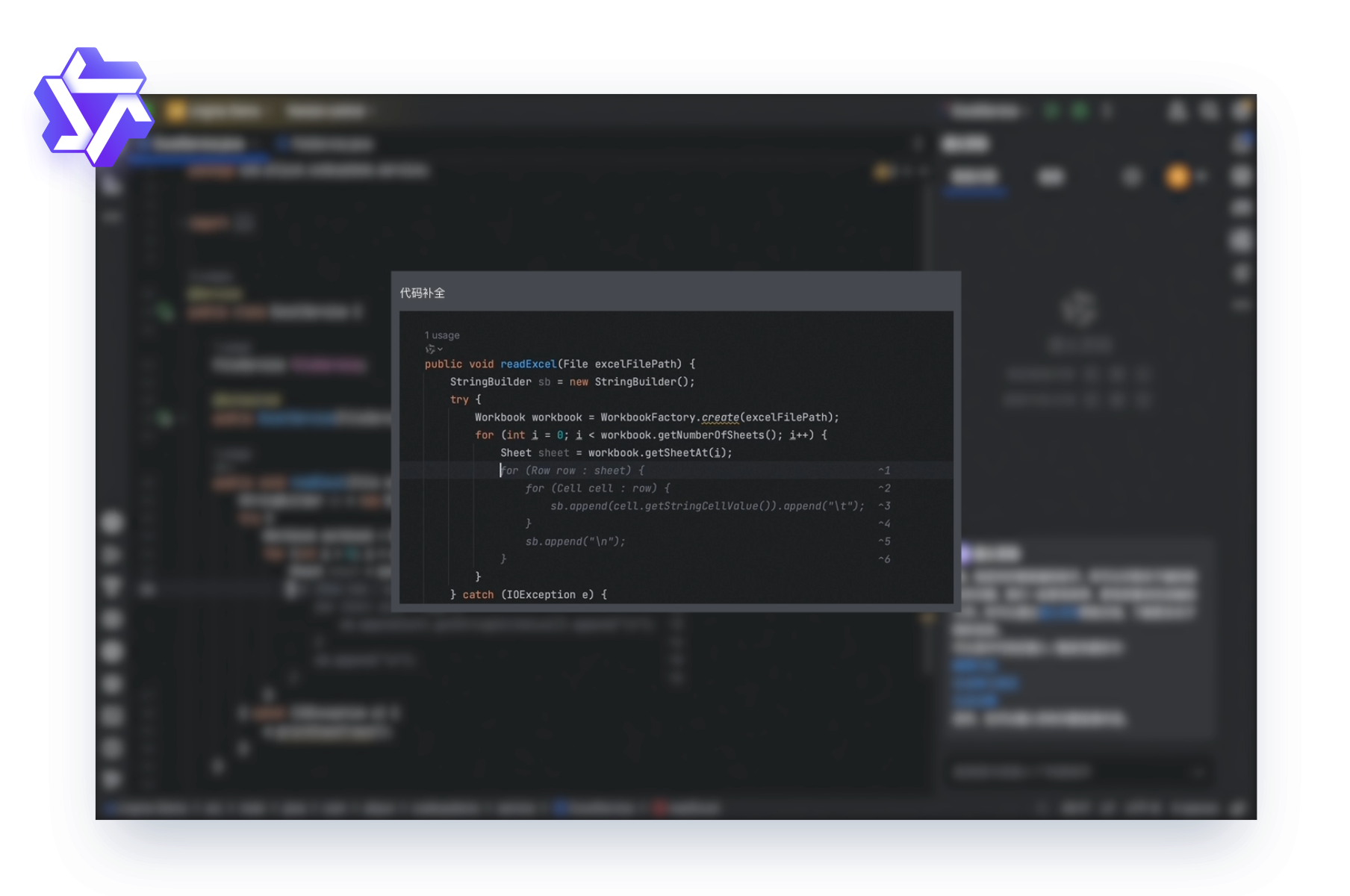
AI 编码,码力全开
基于通义大模型的通义灵码,可实现 200 多种编程语言的行级/函数级的代码生成、补全、优化,并可以自动生成单元测试,提升编码效率和质量。同时结合云效和函数计算 FC 进行代码管理、持续集成、部署发布,让开发者 30 分钟就能完成智能编码、CI/CD、部署上线的完整交付体验。
相关云产品
技术实现参考
① 代码生成:基于您的语言描述或注释, 自动生成代码建议,可一键采纳。
② 代码优化:根据指定的代码,提供优化建议及优化后的代码。
③ 生成单元测试:根据代码生成相应的单元测试,提高代码可靠性。
④ 利用通义灵码还可以进行修复缺陷、补充代码注释和单元测试等,并结合云效和函数计算 FC 进行代码托管和持续集成、部署。
阿里云 AI 助理,您的云端智能伙伴
了解阿里云 AI 助理卓越的技术解决方案,加速云上应用构建
完整的产品体系,为企业打造技术创新的云
全方位的上云超值普惠权益,助力开发者和企业无忧上云
千行百业的公司,与阿里云一起开拓创新



































ISO 27001 信息安全管理体系

ISO 27701 隐私信息管理体系

SOC1/2/3报告 第三方审计报告

工信部云计算服务能力评估

PCI DSS 支付卡产业数据安全标准

公安部网络安全等级保护
数字经济时代,云计算为创新提速
引领市场
自 2009 年创立之初,阿里云就提出“云计算,让计算成为公共服务”,并坚持通过云的弹性和自服务能力支持企业敏捷创新。当前阿里云服务全球 500 万客户,包括 38%(190家)世界五百强企业, 80% 中国科技企业, 65% 专精特新“小巨人”企业;阿里云服务的开发者达 1000万。
技术先进
飞天是阿里云自主研发、国内自研的云计算操作系统,编排调度百万级服务器,单集群调度规模超十万台,具备 EB 级数据存储能力,并通过 CIPU 率先实现虚拟化“0”损耗,提供业界先进的计算性能,既满足客户严苛的业务要求,又提供高性价比服务。
稳定可靠
阿里云为全球 29 个地域、87 个可用区的客户提供稳定可信赖的产品技术。弹性计算单实例可用性 SLA 高达99.975%,数据存储设计可靠性高达12个9,提供稳如磐石的客户体验。
安全合规
亚太合规资质俱全的云服务商之一,从基础设施安全、内核平台安全、系统服务安全、云安全产品四个层面,保障千行百业客户的业务安全在线。拥有权威认可的原生安全能力,根据 2021 年 Gartner 报告,安全能力全球居前列。
数据来源:Gartner 2023年4月发布 《Market Share: IT Services, Worldwide, 2022》;业务实况统计数据;Gartner 2021年11月发布《Gartner Solution Scorecard for Cloud Integrated IaaS and PaaS》